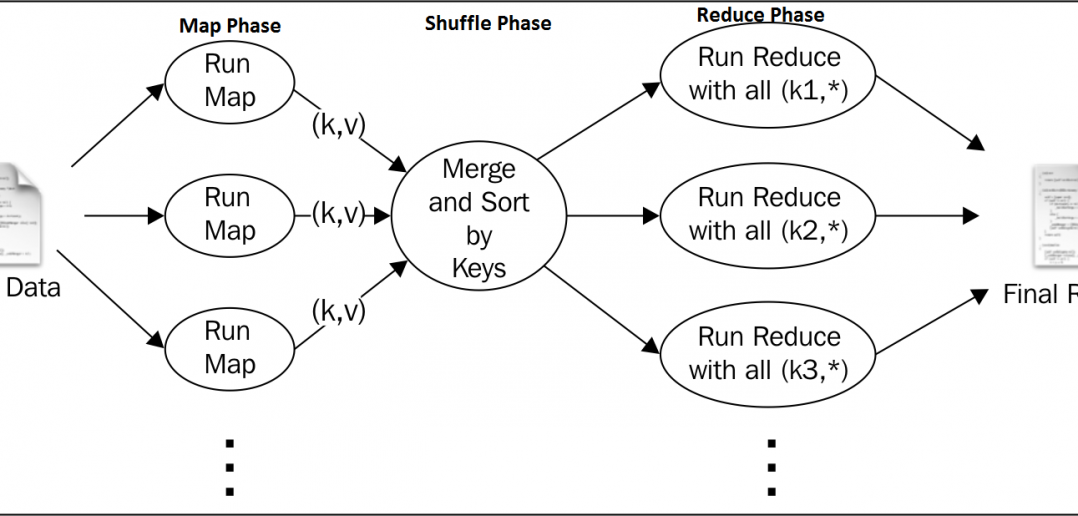
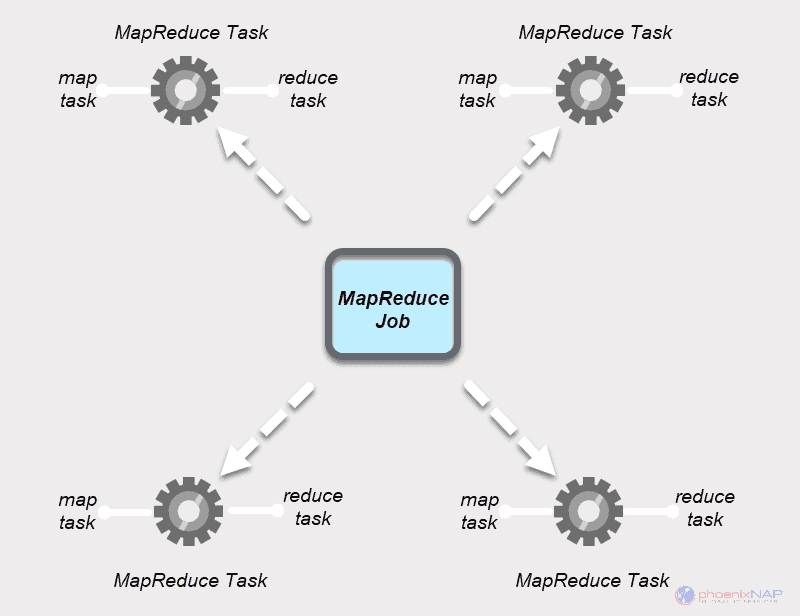
Anatomy Of A Map Reduce Job Run. It's very short, but it conceals a great deal of processing behind the scenes. This section uncovers the steps Hadoop takes to run a job. This is the timeline of a MapReduce Job execution: Map Phase: several Map Tasks are executed. You can run a MapReduce job with a single line of code: JobClient.runJob (conf). Hence, an interleaving between them is possible. Anatomy of a MapReduce Job Run. Anatomy of a MapReduce Job Run. In this post we will discuss the Anatomy of a MapReduce Job in Apache Hadoop.
Anatomy Of A Map Reduce Job Run. Leverage your professional network, and get hired. Anatomy of a MapReduce Job Run. Map Reduce jobs run on Hadoop clusters, which are made up of many nodes (computers). This method call conceals a great deal of processing behind the scenes. Task Execution – Each worker executes its assigned tasks in parallel, using the input data provided by the user during assignment. Anatomy Of A Map Reduce Job Run.
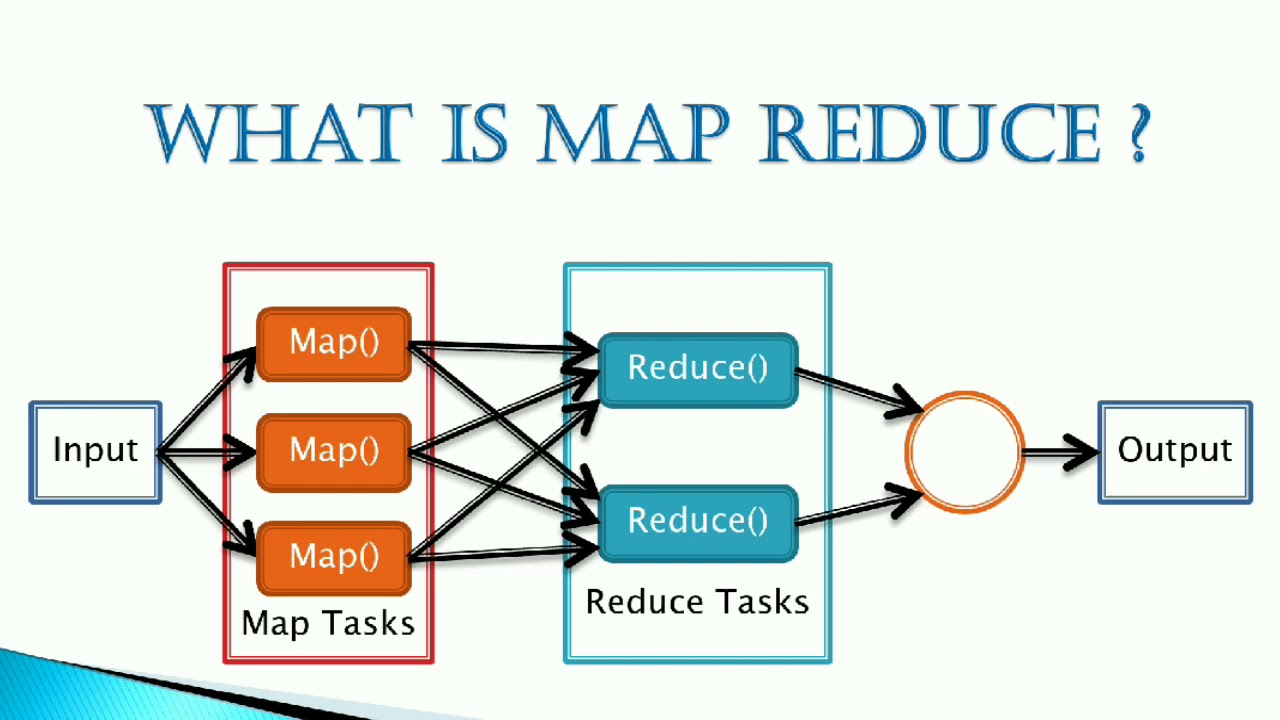
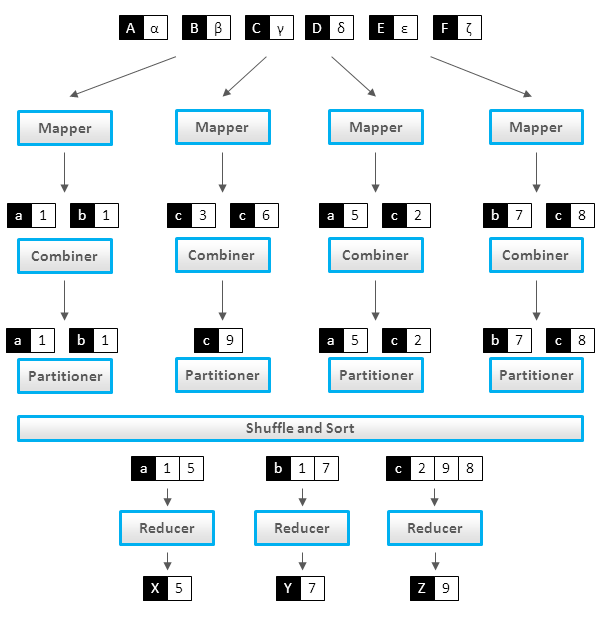
We now focus our discussion on the Map Phase.
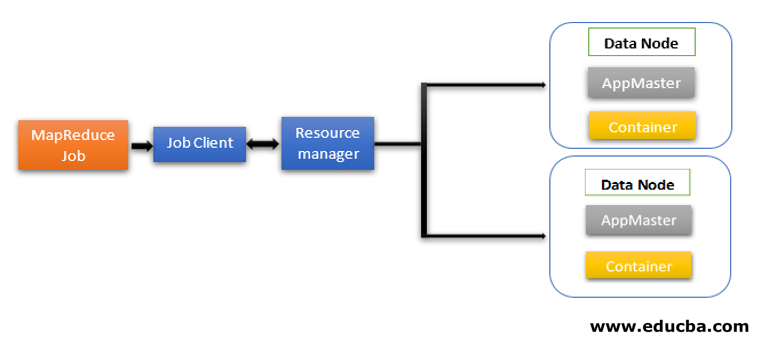
Anatomy of a Map-Reduce Job Run : Hadoop Framework comprises of two main components : Hadoop Distributed File System (HDFS) for Data Storage.
MapReduce是如何工作的?MapReduce的|工作和阶段 – 金博宝官网网址
Hadoop Map-Reduce Explained with an Example – Data Analytics
What is Hadoop Mapreduce and How Does it Work
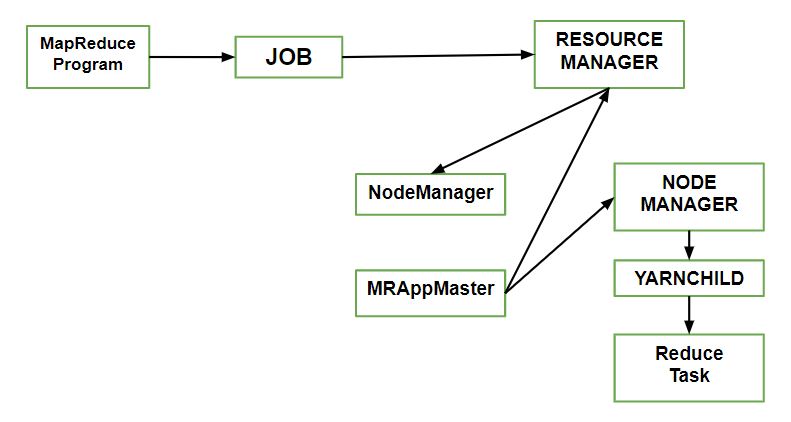
Cómo se ejecuta el trabajo en MapReduce – Barcelona Geeks

(Hadoop) MapReduce: More Power, Less Code – Open Source For You
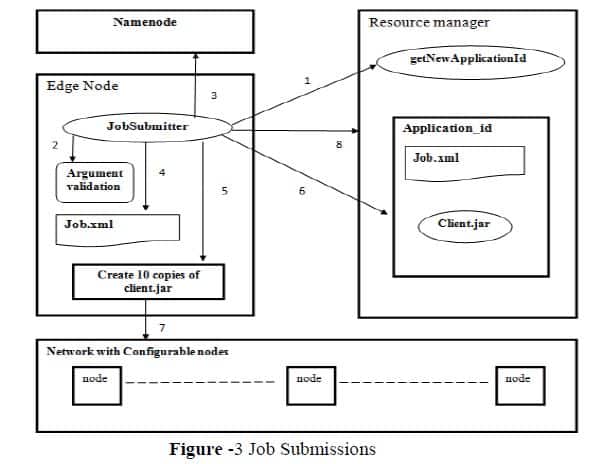
Anatomy of a MapReduce Job – Big Data Analytics News
Elastic MapReduce Job Flows…
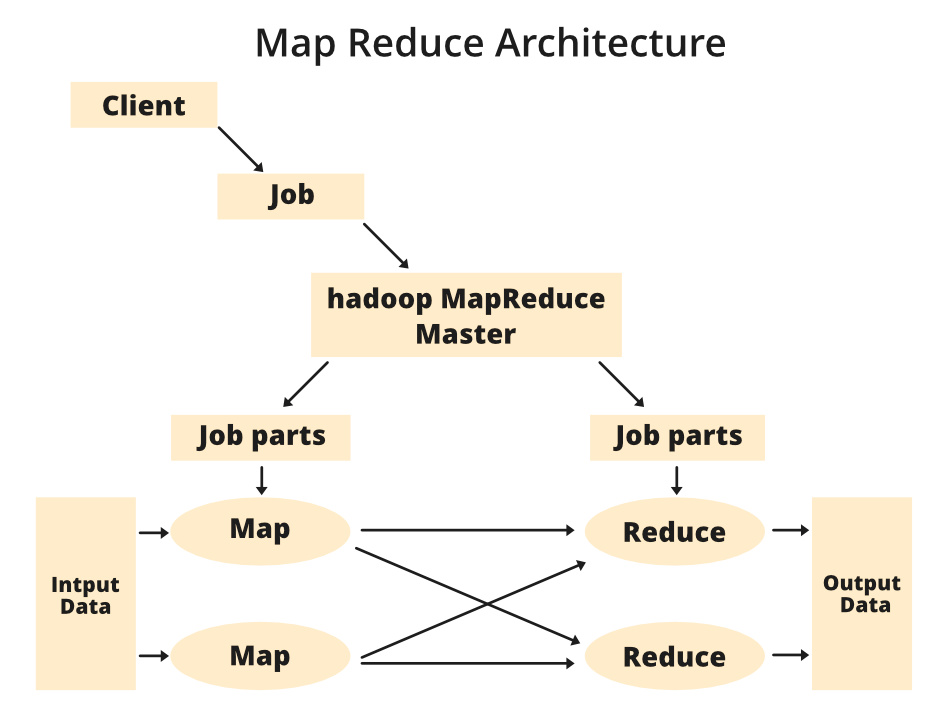
MapReduce Architecture – GeeksforGeeks

PPT – O'Reilly – Hadoop : The Definitive Guide Ch.6 How MapReduce Works …
Anatomy of a MapReduce Job | LaptrinhX

MapReduce workflow super detailed explanation – Programmer Sought

Introduction to MapReduce – Dinesh on Java
Anatomy Of A Map Reduce Job Run. This article is about how anatomy of mapreduce job run in Hadoop and Mapreduce jobs are executed in the hadoop cluster and how the distributed parallel processing is achieved by pushing process to data in the framework. Map Reduce jobs run on Hadoop clusters, which are made up of many nodes (computers). Reduce Phase: several Reduce Tasks are executed. Hadoop Framework comprises of two main components, namely, Hadoop Distributed File System (HDFS) for Data Storage and. Let's take a look at the anatomy of a MapReduce job run.
Anatomy Of A Map Reduce Job Run.